

















The launch of the BJS Award 2025
A celebration of excellence in surgical science, the BJS Award recognises a discovery, innovation or scientific study that has changed…
Read More 
OSRC is active in building multi-disciplinary research teams to explore the implementation of information technologies and artificial intelligence in medical research. Our aim is to explore and develop new tools for medical research. OSRC provide research opportunities for medical students. Anyone can join OSRC and develop research skills.

As we share this planet, we must share resources to survive. Knowledge is the most precious resource. OSRC aims to reduce the knowledge gap between developed and developing countries through courses, workshops and boot-camps to build research skills and resources. OSRC is an open university by and for you.

OSRC have established a vast international network of researchers, physicians, surgeons, data scientists, IT engineers, healthcare providers and administrators. Our experience in innovative medical research and bioinformatics research, is growing with time as well as the number of our researchers. We have plenty of offers to our partners.
OpenSourceResearch Collaboration (OSRC) aims to close the gap between the rapidly evolving information technology sector and the slowly moving healthcare sector.
Traditional medical research methods cannot solve modern healthcare systems problems. Information technologies have revolutionized many areas of research and development for instance banking and commerce and can therefore change the way in which we are performing medical research.
OSRC is an open platform to explore, develop and validate new tools to conduct medical research. These innovative tools implement information technologies and artificial intelligence. The multi-disciplinary research teams approach and agile project management are two concepts cherished by OSRC.
The OSRC is an open-source product however, it encourages spin off StartUps based on its innovative research. In this model OSRC is an academic institute, incubator and/or accelerator of StartUps. Our members can get involved in the academic research as well as entrepreneurial creativity, leadership, and problem-solving activities.

OSRC helps organizations and individual entrepreneurs to develop their businesses by providing a range of services starting with training. OSRC is thus a catalyst tool for regional and national economic development.
OSRC is not not only incubator of good ideas, but also an incubator to develop skills in leadership, teaching, administration and communication.
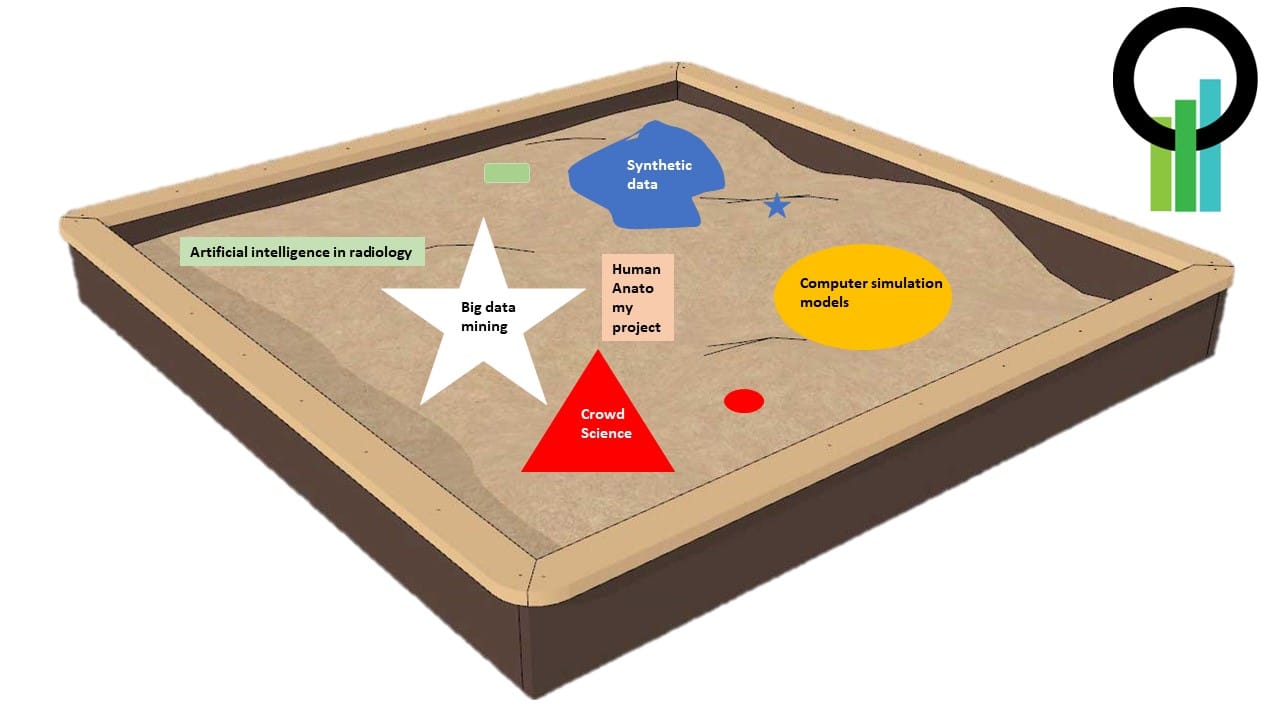
A sandbox is a testing environment that isolates untested code changes and outright experimentation from the production environment or repository. Sandboxes replicate at least the minimal functionality needed to accurately test the programs or other code under development.
With access to data, ideas and medical industry, OSRC provides a unique international sandbox.
In network science, a hub is a node with a number of links that greatly exceeds the average. OSRC connects a large network of researchers, to-be-researchers and students with academic centers and medical industry to develop new tools for medical research.
With thousands of followers, users and members, OSRC‘ network effect is growing fra day to day.


Automated page speed optimizations for fast site performance